
DevOps и Site Reliability Engineering – модные направления, которые считают как конкурентами так и очень похожими между собой.
Рассмотрим, чем же они отличаются друг о друга:
DevOps создавалась как комплекс инструментов призванных убрать пропасть между разработкой и эксплуатацией ПО и не содержит четких инструкций достижения успеха. Т.е. DevOps представляет собой как бы схематическое описание системы, а нюансы реализации ложатся на автора.
SRE реализует философию DevOps и имеет гораздо больший набор условий по оценке и нормам качественной взаимодействия разработчиков и отдела эксплуатации. Опишем наглядно на примере основные элементы DevOps и соответствие им в SRE: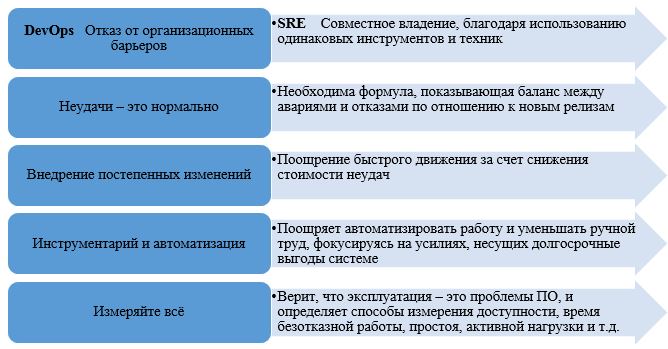
SRE и DevOps не являются конкурирующими методиками, а скорее всего являются симбиозом обеспечивающем предоставление эффективного программного обеспечения.
SRE состоит из уровней обслуживания (SLI) и целей уровней обслуживания (SLO).
SLI – измерение временного отрезка, например задержка запроса, производительность либо количество сбоев на запрос.
SLO – величина успеха SLI за конкретный временной отрезок, скоординированный заинтересованными сторонами.
Взаимное согласие о величине услуг (SLA) это не непрерывная задача SRE, SLA – это гарантии поставщика услуг клиентам по поводу доступности и решений ситуаций, в случае которых он не сможет предоставить оговоренный перечень услуг.
SLA обыкновенно проходит согласование между руководствующими сторонами для потребителей услуг и обеспечивает меньшую доступность чем SLO. Ведь понятно, что предпочтительнее сначала разрушить фактически свой SLO, до того как рухнет SLA потребителей услуг.
SLI, SLO, SLA бок о бок переплетены с элементом DevOps – «измерить все», что подтверждает утверждение – SRE осуществляет DevOps.
Желание максимизации стабильности системы приводит к нереальным показателям надежности из-за ограничения скорости внедрения нового функционала клиенту. Поставщикам услуг, желающим предложить множество новых функций, стоит остановиться на менее строгих SLO и продолжить внедрение в случае возникновения ошибки. Владельцы сервиса, склоняющиеся к надежности, могут выбрать более высокий SLO и признаются, что дискредитация этого SLO задержит релизы функционала. SRE количественно определяет этот уместный риск как «бюджет ошибок». При расходовании бюджета ошибок ориентир переходит от создания функционала на увеличение безопасности.
Весомым элементом SRE считается трудозатраты, бюджет на трудозатраты и методы уменьшения трудозатрат. Трудом называют деятельность по обеспечению продуктивности услуги. Кроме того, эта деятельность имеет свойство быть ручной, периодической и может увеличиваться пропорционально росту услуге.
Бюджет на труд и трудозатраты связаны принципами DevOps «измерить все» и «убрать организационные барьеры». Итоговый принцип SRE – (CRE) Customer Reliability Engineering, основа которого, обучить SRE клиентуру и потребителей. На примере Google, которые при возникновении проблем у потребителей в случае использования системы нестандартно, вынуждены были тормозить инновации и содействовать в решении трудностей. Стало необходимостью обсудить SRE и привлекать клиентов к схемам работы SRE и для того, чтобы они могли использовать их на практике.
SRE перекликается со следующими принципами DevOps, как «устранение организационных барьеров» и создаёт всеобщее обязательство всех участников в форме совместных SLO.
About The Author
Виктор Карабедянц
ИТ директор (CIO), руководитель нескольких DevOps команд. Профессиональный руководитель проектов по внедрению, поддержке ИТ систем и обслуживанию пользователей.