
В последние годы в области мониторинговых приложений наблюдается оживление. Как проиллюстрировано в популярном графике от BigPanda, во многих мониторинговых техниках, продукциях и смежных компаний произошел «взрыв».
В этой статье речь пойдет о платформе, которая, как нам кажется, поможет понять фундаментальные техники и ценности, предложенные различными продуктами мониторинговых приложений. Но для начала, давайте рассмотрим эмпирические факторы, которые стали причиной этого возрождения:
Компании во всех вертикалях индустрии значительно зависят от программного обеспечения; данный факт освещен во многих статьях, таких как: «Все индустрии стремительно превращаются в техиндустрии». В результате, постоянно растет спрос на лучшие продукты мониторинга, которые обеспечат повышенное время работоспособности и ускоренное реагирование на ошибки для важных бизнес приложений.
Современные приложения формируют значительно больше метрики. Например, в 2012 Netfix преодолел предел в 2 миллиона определенных временных рядов, Spotify — 100 миллионов в 2015. В сравнении с гигантами SaaS, даже если среднее современное приложение генерирует на порядок меньше метрики, все равно выходит тысячи временных рядов и миллионы метрик!
Технические основы мониторинговой продукции значительно изменились. База данных временных рядов, усовершенствования ядра Linux и машинное обучение — это малая доля ключевых технологических продвижений, влияния мониторинговых продукций.
Понимая движущие факторы лучшей мониторинговой продукции, давайте сосредоточимся на разработке более легкого фреймворка, чтобы понимать количество вариантов на рынке.
 Рисунок 1. Разнообразие приложений мониторинга
Рисунок 1. Разнообразие приложений мониторинга
Понимание видов мониторинга
Столкнувшись со сложной проблемой, руководители фирм, топ-консультанты и светлые умы по всему земному шару часто полагаются на известный фреймворк «2×2» для установки более простого вида. Мы будем следовать их примеру и разработаем 2×2 классификацию видов мониторинга. В частности, мы сравним и классифицируем:
- Мониторинг на уровне сервиса и на уровне инстансов.
- Black-box и White-box мониторинг
До того, как мы обсудим данные категории, стоит установить многоуровневое представление о современных программах (как показано на рисунке 2)
- Во-первых, пользователи взаимодействуют с любым бизнес-приложением через такие frontend интерфейсы, как мобильные приложения, браузеры, ТВ приложения и потребительские устройства (Alexa и т.д.)
- Взаимодействие пользователей сообщается в backend приложение (т.е. сторона сервера) через API. Запрос каждого пользователя осуществляется посредством сложного взаимодействия между многими сервисами. Услуги — это логическая группировка функционально эквивалентных инстансов. Например, несколько инстансов могли бы предоставлять сервис REST для списка предметов в корзине. Так как все эти инстансы служат одной конечной точке (или URI), их можно сгруппировать в сервис «список предметов в корзине». В современных приложениях, сервисы — это естественные группировки функциональности приложения; таким образом, сервисы — это критический уровень абстракции в иерархии приложения.
- Работа сервисов осуществляется множественными экземплярами кода, работающего внутри VM, контейнеров или «голых металлических» операционных систем
- Инстансы функционируют в инфраструктуре, которая образует самый нижний уровень.
Рисунок 2. Иерархический взгляд на современные облачные приложения
В этой статье мы уделим внимание бэкенд мониторингу. В результате, мы пропускаем такие техники, как синтетические транзакции или методы для мониторинга таких интерфейсов пользователей, как мобильные приложения.
Мониторинг уровня обслуживания
Категория также называется объективно-ориентированный мониторинг.
Для бэкенд мониторинга, подход мониторинга уровня обслуживания начинается автоматическим открытием сервисов, т.е. группировка функциональных эквивалентных инстансов. Зависимость среди сервисов – это использование таких техник, как анализ сетевого соединения или распределенная трассировка. Как только сервисы и их зависимости установлены, мониторинг уровня обслуживания может установить топологическую карту приложений (смотри рисунок 3)
Рисунок 3. Пример топологической карты приложения в центре обслуживания приложений Netsil (AOC)
В топологической карте приложения, каждый узел представляет сервис, а каждая грань представляет зависимость между сервисами, установленную сетевым соединением. С этой топологической картой, операционные команды (Инженеры по надежности сайта (SRE), инженеры по развитию, DBAs и т.д.) могут с легкостью определить объективный уровень сервиса (SLO) для таких золотых сигналов, как задержка сервиса, работоспособность, частота ошибок и перегрузка. Важность мониторинга уровня обслуживания подчеркивали многие известные SRE практики в их числе Брендан Грег из Netflix, Кайл Брэндт из StackExchange и Google SRE bible.
Мониторинг на уровне инстансов
Категория также называется диагностически-ориентированный мониторинг
Это привычный мониторинг, который включает в себя сбор логинов и метрик из индивидуальных инстансов (код приложения,VM, контейнеры и тд) и лежит в основе компонентов технического обеспечения. Мониторинг уровня обслуживания отслеживает SLO, а уровень инстансов необходим для диагностик. В конце концов, сервисы — это абстрактные группы и для диагностики здоровья сервисов нам нужны метрики, обуславливающие инстансы и их операционную среду.
Изначальная эволюция в мониторинге уровня экземпляра была программой базы данных временных рядов и техники обработки потоков для того, чтобы справиться со значительным ростом в метриках, улучшить выполнение метрик для повторного сбора и предоставить мощный реальный аналитический механизм.
White-box мониторинг
Следующая категория подходов мониторинга зависит от того, нужно ли изменять код приложения или нет. Если методы мониторинга требуют изменения кода во время осуществления работы, то они могут быть названы white-box мониторинг. Некоторые популярные техники в этой категории включают:
1.Для методов мониторинга, основанных на логах, необходимо, чтобы логи были внедрены в код.
- Такие техники управления работой приложения (APM), как применение байт-кода требует изменение в работе (или времени загрузки).
- Использование такого фреймворка как statsd для настройки кода и отправление пользовательских метриков в аналитическом механизме.
- И наконец, для большинства методов распределенного трассера, который требует «обвертывания» кода или API-вызовы с транзакцией, определяющей метаданные. Google Dapper остается наиболее значимой работой по дальнейшему чтению о распределенной трассировке.
Black-box мониторинг
Как вы уже догадались, этот набор техник не предусматривает изменения кода. Это означает, что код не изменяется ни во время выполнения, ни во время работы. Варианты для того, чтобы разобраться в приложении без изменения кода включают:
- Поддержка использования операционной системы для того, чтобы разобраться в работе приложения. В дополнение к базовым метрикам, связанных с cpu, памятью, диском, сетью и т.д., большинство современных операционных систем предоставляют усовершенствованные способности, чтобы разобраться в работе приложения. В широком смысле эта идея схожа с применение байт кода, разница только в том, что операционная система предоставляет датчики и подсказки для того, чтобы лучше понимать приложение. Для Linux следующая версия ядра значительно расширяет возможности обеспечения видимости в приложении. Мы хотели бы посоветовать вам в этом контексте ознакомиться со всесторонним анализом улучшения ядра Linux под авторством Брендана Грегга.
- Использование сетевых коммуникаций для того, чтобы разобраться в сервисах и приложениях. С ростом ориентированной на сервисе и микросервисной архитектуры, сложность перешла из кода в сеть. Всестороннее понимание состояния «здоровья» и показателей производительности приложений может быть получено, если посмотреть на такие метрики сетевой связи, как пропускная способность, время ожидания, повторные передачи пакета, размер байта запроса / ответа и тд. Этот подход не требует какого-либо изменения кода и полагается на хорошо установленные методы захвата удаленного пакета, который поддерживается как операционной системе Windows, так и на Linux. Netsil – первопроходец в данном подходе.
Фреймфорк классификации приложений мониторинга
 Рисунок 4. Классификация методов мониторинговых приложений.
Рисунок 4. Классификация методов мониторинговых приложений.
Мы пообещали представить всю эту сложность во всемогущей фреймворк 2×2. Рисунок 4, показывает методы мониторинга, классифицированных в: black-box и white-box и уровень обслуживания, и уровень инстансов. Далее несколько важных пунктов на заметку:
- Методы black-box мониторинга также могут принимать пользовательские метрики из приложения (например, используя statsd)
Мы применили APM или, более конкретно, байт-кодовую технику, основанную на методах, в категории White-box + категории уровня инстансов, поскольку они требуют изменений во времени выполнения приложения и собирают информацию об отдельных экземплярах кода.
Методы распределенной трассировки, большинство из которых опираются на изменения кода, предоставляют анализ нескольких сервисов. Они не обязательно создают какие-нибудь группы инстансов в сервисах, но по-прежнему обеспечивают высокоуровневый анализ потока запросов к API для нескольких инстансов. Таким образом, мы разделили их на такие категории, как white-box + мониторинг уровня обслуживания.
Наконец, обратите внимание на компании, упомянутые в фреймворке. Компании и их продукты используют сочетание методов мониторинга. Так, что даже если компании упоминаются в качестве примера в одной категории, их предложения могли бы почерпнуть пользу сразу из нескольких методов. Netsil, например, использует комбинацию захвата сетевых пакетов для автоматического обнаружения сервисов и использует других агентов, чтобы собрать конкретный уровень метрик, таких как статистика контейнеров docker. Так Netsil способен обеспечить как уровень обслуживания, так и уровень инстансов.
С простой классификацией 2х2, давайте рассмотрим, как он может быть использован искусственными образами dev и Ops, чтобы оценить широкий выбор методов мониторинга.
Сопоставление искусственных образов методов мониторинга
Есть два простых фактора, которые могут помочь сопоставить фреймворк и искусственные образы и выбрать правильный набор продуктов мониторинга.
- Уровень ознакомленности с кодом приложения: команды разработчиков, реализующие сервисы, близко знакомы с кодом. Так что для команды разработчиков, методы white-box такие, как применение байт-кода и логов обеспечат осмысленное понимание. А для команды ops (SRE, devops инженеры, DBA и т. д.), которая в первую очередь унаследует сервис по производству, код — это black-box. Такое представление уровня кода, как функция вызова стека или замысловатые логи имеют ограниченную ценность для ops команд, которые не знакомы с логикой кода. Для ops команд являются идеальными методы black-box мониторинга, которые не требует каких-либо изменений кода или понимания уровня кода.
- Количество услуг, которые должны быть проверены: если вы опять же команда разработчиков, ответственных за несколько услуг, то на уровне экземпляра и white-box метрики будет достаточно. В то время как для ops групп, отвечающих за здоровье нескольких десятков услуг, уровень обслуживания и black-box мониторинга будут более продуктивными. Мониторинг каждого отдельного экземпляра просто затянет ops команды в тысячу бессмысленных предупреждений, повлекших за собой массовое ослабление бдительности. Для ops команд, анализ уровня обслуживания на задержки, пропускную способность, ошибки и др. являются более значимыми.
Короче говоря, уровень обслуживания + методы black-box мониторинга идеально подходят для Ops команды, ориентированной на «здоровье» и эффективность многих технологических услуг. В то время как уровень экземпляра + white-box методы являются более значимыми для команды разработчиков, заинтересованных в производительности и работоспособности отдельных услуг на уровне кода. Оба лица могут углубляться в метрики на уровне инстансов для диагностики, планирования ресурсов и т. д. И обе команды dev и Ops могут использовать механизмы распределенной трассировки white-box для анализа отдельных операций, протекающих через приложение.
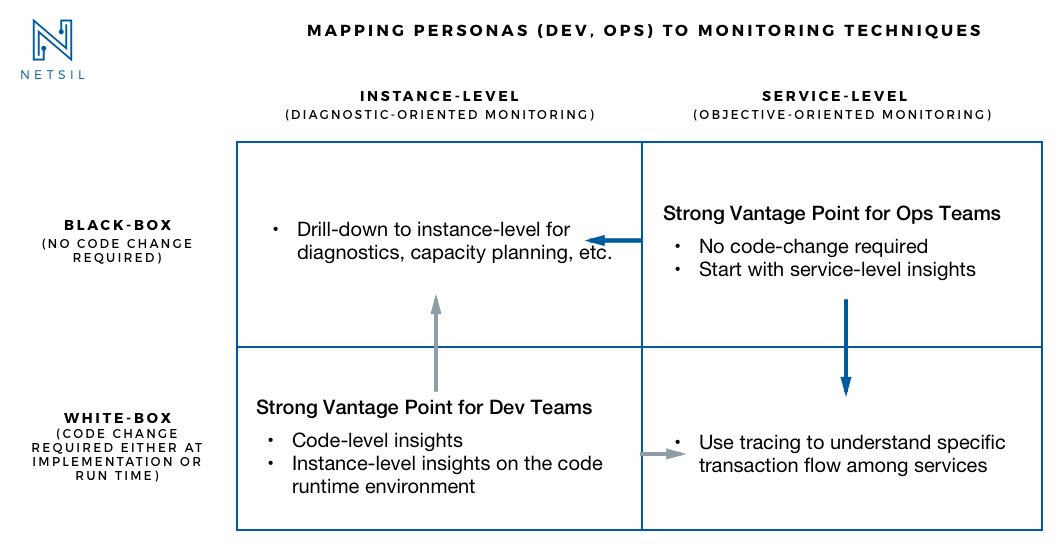 Рис. 5. Сопоставление образов методам мониторинга
Рис. 5. Сопоставление образов методам мониторинга
Заключение
Нашей целью в данной статье было предоставить вам простой фреймворк, чтобы помочь сориентироваться и выбрать правильные методы мониторинга. В Netsil мы разработали мощный, элегантный подход, который является комбинацией:
- Black-box мониторинга, т.е. не требует каких-либо изменений кода, и
- мониторинг уровня обслуживания, т.e автоматически обнаруживает сервисы, что позволяет определить цели уровня обслуживания и включает детализацию метрики уровня экземпляра (инстанса).
Мы верим, что мониторинг уровня обслуживания Netsil является фундаментальной необходимостью для ops команды, управляющей современными облачными приложениями. Мы хотели бы призвать вас загрузить и начать работу с оперативным центром приложения Netsil (АОС) и сотрудничать с нами для повышения надежности и производительности критически важных бизнес-приложений.
About The Author
Виктор Карабедянц
ИТ директор (CIO), руководитель нескольких DevOps команд. Профессиональный руководитель проектов по внедрению, поддержке ИТ систем и обслуживанию пользователей.