
В продолжение статьи…
Архитектура решения
В данный момент у нас нас nginx + apache через mod-php передается выполнение php скриптов на сам интерпретатор. Такое решение сильно разгружает наш сервер за счет того, что статика отдается nginx. Но здесь есть небольшая проблема, такая как apache. За тем, что это тяжелое приложение несмотря на то, что это сервер, который уже очень много лет держит лидирующие позиции и раза в 3-4 опережает nginx по использованию в мире. Но он гораздо более тяжелый если не затюненый, а если даже затюненый – памяти все-равно пожирает заметно больше, для наших нужд – это излишество. И nginx, как более легкий прокси-сервер сможет отлично справится, чтобы без apache передавать php код на интерпретатор php-fpm. Таким образом, мы избавляемся от прослойки тяжелого apache, но есть проблема которую надо будет решить передача переменных окружения. На данный момент эти значения передаются через htassess apache, и если от этих переменных отказаться, то apache сам собой уходит. Правила по поводу rewrite и доступов будут перенесены в сам конфиг nginx, а это кстати хорошо потому что никаких частей конфига в виде htassess не будет в самом корне приложения. То есть к нему теоретически можно получить доступ, то есть доступ мы естественно обрезаем, но мало ли и лучше конечно чтобы приложение конфигурировалось исключительно привилегированными пользователями, только из каталога etc и только оттуда. Ну а переменные окружения в php-fpm Мы будем передавать как-то иначе. Либо через bash-RC, либо надо узнать про импорт у команд, которые уже имеют представление, как это делать.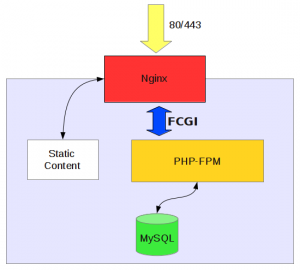
Solr
По поводу solr вряд ли что-то смогу сказать. Знаю, что есть у него такой конкурент как ElasticSearch. Но мне сложно судить, потому что я не работал с этими технологиями настолько близко, чтобы понять, функциональные отличия между ними.
Построение взаимодействия между окружением разработки и продуктивным окружением.
Есть Дев зона и production зона в КАРЕГИ. Хорошо было бы иметь staging зону – PreRelease, которая максимально копировала бы production. Для того чтобы точно знать время развертывания приложения и особенности, с которыми столкнемся именно в рабочей среде. То есть увидеть то, что в Дев сложно протестировать. В нашем случае – это одно приложение – КАРЕГИ сайт. Мы уже знаем вдоль и поперек, сколько времени и где оно разворачивается, какие нужны конфигурационные файлы, какие проверки проходят перед залитием кода, точнее во время исполнения этого кода. Поэтому я не уверен, так ли важно иметь эту PreRelease среду и кто и что в ней будет тестировать. Пока достаточно дев среды, в которой тестируют наши QA-инженеры. Поскольку просто баснословное количество страниц на сайте, очень сложно охватить все области где можно нащупать какую-то ошибку. QA скачивают страницы и смотрят код, который возвращается. Должен быть код 200. Но 10000 страниц, 100 000 страниц они скачают, но 100 001 выйдет 500 или 404ошибка, а они ее не проверят. Бывают такие случаи. Которая прилетает потом нам в виде Emergency. Радует то, что последнее время это случается значительно реже.
Среда разработки каждого программиста
1 KVM сервер (дев сервер, по сути это часть KVM ) на котором так или иначе развернуты Дев-пространства. То есть какой-то LVM раздел, с выделенным местом под каждого программиста. Там лежит по копии сайта на каждого программиста. Использование индивидуальных виртуальных машин, как по мне – гораздо продуктивнее, хотя, может быть, кто-то скажет, что это расточительство. По поводу виртуальных машин. Кто-то использует Vagrant (своего рода консольный VirtualBox) и деплоит боксовские контейнеры – не вижу смысла в применении у нас. У нас есть proxmox. Не уверен, что можно его автоматизировать, но точно можно создавать какие-то шаблоны и потом их разворачивать, а не ставить систему каждый раз. Есть такие технологии как OpenStack, CloudStack, OpenAbular??, Ubuntu OpenStack . Я смотрю в сторону Ubuntu OpenStack и MaaS – metal as a service. Эта технология активно пропагандируется компанией Canonical и позволяет нам воедино связывать несколько серверов , что позволит нам не заказывать Dell сервера, в которых стоят 2600 серии процессоры которые многоядерные, но низко производительные, если смотреть по частоте на одно ядро. Для виртуальных машин 2,4 ГГц – это мало. Нужно брать или другие Dell: например 530, где можно установить Xeon 12 или 16 серии, который позволяет разогнаться до 3,5 – 3,8 ГГц .при 12 ти потоках Это будет большой скачок для нас. Либо, если нужна частота еще выше, брать не Dell сервера, в которых будут стоять core-i7 с частотой от 4-4,2 ГГц (быстрее сейчас ничего нет) 8 потоков и объединять их в кластера. Затем разворачивать виртуальные машины прямо на них. Причем сделать шаблоны, когда нажимаешь и с одной кнопки разворачивается CentOS 7 или 6. Тут же разворачивается образ, автоматически подтягивается IP адрес из пула, который заранее забит, настраиваются все маршруты, IP желательно чтобы привязывался. За 30-60 секунд мы получаем готовую виртуальную машину, которую можно развернуть с помощью Puppit (Это более Энтерпрайз решение которое идеологически нам ближе так как написано на Руби)
 У нас активно будет внедряться Докер. CI планируется с помощью докера (конференция CodeID – внедрение CI на базе Докер контейнеров. Если кратко — работает так: push в репозиторий в ветку мастер, веб хук с репозитория дергает систему CI, которая начинает запускать задачи. Например скачку докер образа, запуск в нем контейнера с кодом или без, возможно код подтянется в процессе или он где-то лежит и его нужно просто примонтировать, запускает какие-то юнит тесты, функциональные и другие тесты и выдает какой-то результат, по которому можно принять решение о деплое кода в production.) Система деплоя контента – Capistrano опять же написана на Руби нас вполне сейчас устраивает. Мы планируем использовать Jenkins. Нужно, чтобы Jenkins после всех проверок правильно дергал Capistrano для деплоя контента на все серверы.
У нас активно будет внедряться Докер. CI планируется с помощью докера (конференция CodeID – внедрение CI на базе Докер контейнеров. Если кратко — работает так: push в репозиторий в ветку мастер, веб хук с репозитория дергает систему CI, которая начинает запускать задачи. Например скачку докер образа, запуск в нем контейнера с кодом или без, возможно код подтянется в процессе или он где-то лежит и его нужно просто примонтировать, запускает какие-то юнит тесты, функциональные и другие тесты и выдает какой-то результат, по которому можно принять решение о деплое кода в production.) Система деплоя контента – Capistrano опять же написана на Руби нас вполне сейчас устраивает. Мы планируем использовать Jenkins. Нужно, чтобы Jenkins после всех проверок правильно дергал Capistrano для деплоя контента на все серверы.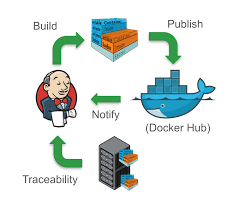
По поводу того, как будут реализованы Докер Контейнеры в этой схеме у меня пока мысли нету, потому что тут мы еще не обговаривали. Как я понял, Jenkins будет использоваться в паре с Марафон (framework от компании Mezosfera, которая по сути работает над таким окружением, как Methos. Над ним работает apache Foundation, но именно Мезосфера берет methos как основу для своей среды enterpriseDCOS. Ну и там внутри – кронос, который по сути заменяет крон и нужен по сути для запуска заданий или контейнеров, которые планируют работать недолго и запускаются с с определенной периодичностью) Марафон – вещь, которая больше нужна для каких-то running services – то есть заданий, которые запускаются и должны работать постоянно. В случае непредвиденного падения они должны быть перезапущены и при желании, они могут быть размножены. То есть можно сделать Scale от 1 до 3-4 экземпляров и все они будут работать одновременно, если конечно приложение позволяет это делать.
Разработка ПО на своих машинах
Нам кажется – идея плохая. Поскольку могут наехать и отобрать компы. От этого обезопасились вынесением среды разработки далеко за пределы страны. Это очень важно. Рабочая станция программиста, как и любого другого сотрудника в нашей компании – это не более чем терминал доступа. Среда разработки должна быть централизована и храниться на серверах, которые админим мы.
Проблемы различных версий php, модулей и прочего.
На локальной машине мы тоже даем рута. Но среда разработки у нас централизованная, а значит мы им создаем окружение: им нужны модули, они нас просят, мы им ставим. Если мы прийдем к тому, что у каждого разработчика есть своя виртуальная машина, то дав им права рута туда мы можем оградить от лишних задач. Нужно только ограничить доступы с виртуальных машин, чтобы они под рутом не смогли зайти куда-то еще, куда им не нужно.
По тестам
От ДевОпс отдела мало что зависит, потому что тесты пишут программисты. У нас с этим проблема. По правильному – это покрывать код тестами, нужно заранее знать как приложение будет работать. У нас так не бывает. Сначала пишется код, а потом как то пытаются его покрыть тестами. Я не знаю, как ребята будут покрывать тестами свои приложения, в том числе CareID мне не понятно, но посмотрим.
По поводу продуктивной среды
Архитектура баз данных: Галера кластер, это конечно хорошо, но не известно, как поведет себя наша база в кластере, потому что постоянно выполняются скрипты, запись, чтение – очень высоконагруженный проект и даже сейчас используя 48 ядерные процессоры и 1Тб оперативной памяти у нас база уже занимает 2,5Тб и это не предел, и никто не будет ее чистить Так что – невозможно сказать, будет ли переход на галера кластер хорошим решением.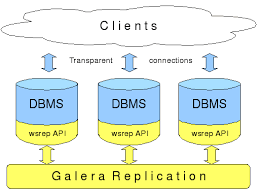
Это обеспечивает отказоустойчивость. Но не понятно.. Как будет проходить синхронная репликация. У нас сейчас мастер-мастер – асинхронная (вообще можно считать, что master-slave, потому что запись идет в один сервер) . Синхронная репликация предполагает, что пока транзакция не пройдет на всех серверах кластера, она считается незавершенной. Это правильно с точки зрения безопасности, но не известно, как будет работать с точки зрения производительности. Галера кластер у нас уже используется для менее нагруженных решений, таких как payment system и myGarage но как это будет в контексте CareID сайта – не понятно пока.
По системе мониторинга
У нас работает Zabbix. Я считаю, что нужно было оставить OPXU для production, и потихоньку внедрять Zabbix для Дев.
 Cloudflare
Cloudflare
Защищает от ботов. Мы пробовали такое использовать. Наверное, встречали такое, когда заходишь на сайт, защищенный Cloudflare, а там прыгает окошечко, подождите, мы проверим, что вы не бот. По этому у нас своя антипарсинг система, которая всех пускает, а там уже дальше разбирается.
About The Author
Виктор Карабедянц
ИТ директор (CIO), руководитель нескольких DevOps команд. Профессиональный руководитель проектов по внедрению, поддержке ИТ систем и обслуживанию пользователей.