
Twitter «возмужал», когда оборудование от разработчиков вендоров начало управлять центром обработки данных. Предлагаем перевод статьи о маштабах инфраструктуры триттера.
С тех пор мы беспрерывно конструировали и обновляли наш «флот», чтобы пользоваться достоинствами самых новых стандартов в технологиях и эффективности оборудования, с целью получить наилучший опыт.
Текущее распределение оборудования показано ниже: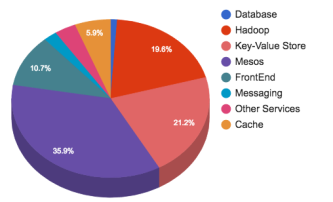
Трафик сети
Мы начали миграцию из стороннего хостинга в 2010, что означало, что нам придется научиться создавать и запускать нашу инфраструктуру изнутри и с ограниченным пониманием нужд главной инфраструктуры, мы начали типы виды сетей, оборудования и разработчиков.
К концу 2010 года мы одобрили нашу первую архитектуру сети, направленную на решение проблем масштаба и сервиса, с которым мы столкнулись. У нас был глубокий буффер ToRs, который поддерживал прерывистый трафик и ядро содержания оценки переключатели без превышения лимита на этом уровне. Таким образом, ранняя версия Twitter поддерживалась некоторыми заметными достижениями разработки, например, рекорд TPS, который мы побили во время Castle in the Sky и World Cup 2014.
Спустя несколько лет мы запустили сеть с POP на 5 континентах и центры базы данных с сотнями тысяч серверов. В начале 2015 у нас появились проблемы из-за изменения архитектуры сервиса и увеличении объемов, в конечном итоге, достигая пределов физического масштабирования в центре базы данных, когда уже тополгия full mesh перестала поддерживать дополнительное оборудование для новых разделов сервиса. Кроме этого, наш существующий центр данных IGP начал неожиданно странно себя вести из-за увеличения масштаба и сложности топологии.
Во избежание этого, мы начали конвертировать существующий центр данных в Clostopology + BGP. Это конверсия, которую нужно совершать в режиме онлайн, но не смотря на усложненность, она была выполнена с минимальным воздействием на сервисы за относительно короткий промежуток времени. Сейчас сеть выглядит следующим образом:
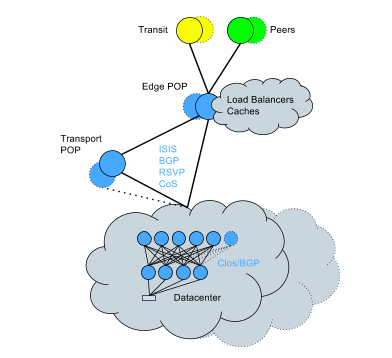 Выдержки из нового подхода:
Выдержки из нового подхода:
- Меньший радиус «поражения» при отказе единичного устройства.
- Возможности горизонтального масштабирования загрузки сети.
- Уменьшена сверхурочная работа маршрутного механизма CPU;
- Более эффективная обработка обновлений маршрута.
- Большая пропускная способность маршрута из-за снижения сверхурочной работы CPU.
- Более детализированный контроль над политикой маршрута.
- Открытый доступ к нескольким известным источникам больше не является причиной основных аварий: увеличенное время согласования времени протокола, проблемы пересмотра маршрута и неожиданные проблемы со сложностью, присущей OSPF.
- Обеспечивает бесконтактные миграции racks (ячеек).
Давайте детальнее посмотрим на нашу сетевую инфраструктуру ниже.
Трафик центра обработки данных
Трудности
Наш первый центр обработки данных был построен при помощи моделирования профилей емкости и трафика из известных систем в colo. Но спустя несколько лет, наши центры обработки данных стали на 400% больше, чем проектировалось в начале. И сейчас, когда наш стэк приложения развивается, а Twitter стал более распространенным, профили трафика также изменились. Первоначальные допущения, диктовавшие нам прежний дизайн сети потеряли актуальность.
Наш трафик растет быстрее, чем мы можем перестроить весь центр обработки данных, поэтому важно создать высоко масштабируемую архитектуру, которая позволит увеличивать объем шаг за шагом вместо одноразовой неподъемной миграции.
Высоко разветвленные микросервисы требуют очень надежной сети, которая справится с большим разнообразием трафика. Наш трафик варьируется от долго живущих TCP соединений до спонтанных невероятно коротких «микровзрывов». Наш первоначальный ответ этим разнообразным примерам трафика заключался в разработке схем пропуска траффика с большим буфером. Но в придачу к этому решению появился новый набор проблем: более высокая цена и повышенная сложность оборудования. Поздние разработки использовали размеры буфера ближе к стандартным и функцию сквозного переключения вместе с улучшенной версией TCP-стека, чтобы лучше обрабатывать микровсплески траффика.
Усвоенный урок
Спустя годы и пройдя через все улучшения, мы усвоили несколько важных вещей:
Проектируйте свой бизнес с запасом по сравнению с плановой нагрузкой оборудования и ПО, а также вносите быстрые и уверенные изменения, если трафик движется по направлению верхней границе вашего планового объема.
Полагайтесь на данные и метрики с целью принять правильное решение и убедиться, что те метрики понятны сетевыми операторами — в частности это важно для локальных и облачных сред.
Не существует такого понятия, как временные изменения или временное решение: в большинстве случаев, временные решения – это ваш технический недостаток.
Базовый трафик
Трудности
Наш базовый трафик значительно вырос год за годом — но все еще заметны всплески в 3-4 больше нормального трафика при его перемещении между центрами обработки данных. Таким образом, мы сталкиваемся с уникальными трудностями, которые не были предусмотрены, например, MPLSRSVP протокол, который предполагает некоторые колебания, но никак не внезапные всплески. Мы потратили много времени на настройку этих протоколов, чтобы получить самое быстрое время ответа. Кроме этого, для управления всплесками трафика мы внедрили расстановку приоритетов. В то время как нам нужно гарантировать доставку клиентского трафика в любое время, мы можем позволить себе отложить поставку низкоприоритетных задач репликации хранилища, у которых есть длительные SLA. Таким образом, наша сеть использует весь доступный объем и эффективным образом использует ресурсы. Клиентский трафик всегда важнее, чем низкоприоритетный внутренний. Более того, для решения проблемы с бинпекингом, связанной с пропускной способностью RSVP, мы внедрили TE++, который при росте трафика создает дополнительные LSP и удаляет их при падении трафика. Это позволяет нам эффективно управлять трафиком между ссылками, при этом сокращая тяжесть управления большим количеством LSP.
Хотя изначально не было никакого инжиниринга трафика, он был добавлен, чтобы помочь нам масштабироваться в соответствии с ростом. Для упрощения мы завершили распределение ролей, чтобы появились разделенные роутеры, отнесенные к основному и второстепенному направлению траффика. Это позволило нам масштабировать экономично, так как нам не пришлось покупать роутеры со сложными функциональными возможностями.
Это означает, что нам нужно соединить всё через корпус и сможем масштабировать горизонтально (т.е. получить много роутеров на сайт вместо только пары, так как у нас есть главный слой для связи всего через него).
Чтобы масштабировать RIB в наших роутерах, нам пришлось ввести отражение маршрута с целью соответствовать требованиям растущего масштаба, но совершая это и переходя к иерархическому дизайну, мы также создали маршрутные отражатели клиентов собственных рефлекторов.
Выученный урок
В течение последних лет мы мигрировали настройки устройства на шаблоны и сейчас регулярно проводим их проверку.
Пограничный трафик
Мировая сеть Twitter прямо связана с более 3000 уникальных сетей во многих мировых центрах обработки данных. Прямая поставка трафика — наш первый приоритет. Мы доставляем 60% нашего трафика для нашего глобального сетевого «костяка», чтобы связать точки и POP (Post Office Protocol), где у нас есть местные front-end серверы, ограничивая клиентские сессии — все с целью быть как можно ближе к клиенту.
Трудности
Мировые события, которые невозможно предсказать, приводят к такому же непредсказуемому всплеску трафика. Эти всплески во время таких важных событий, как спортивные матчи, выборы, природные катаклизмы и другие новостные события, накладывают нагрузку на сетевую инфраструктуру (в частности фото и видео) без предварительного предупреждения. Мы обеспечиваем объем для таких событий и планируем использование всплесков — часто 3-10 нормальных пиков, когда основные мероприятия в регионе на носу. Из-за нашего значительного года роста трафика, успевать за объемом может быть действительно трудно.
Работая с сетями наших клиентов где только возможно, появляются свои трудности. К удивлению, часто сети и провайдеры предпочитают связь вдалеке от «домашнего» рынка или из-за их маршрутных политик, что приводит трафик в POP, находящихся вне рынков. И пока Twitter открыто сотрудничает со всеми клиентскими сетями, мы видим работающий трафик, в отличие от ISP. Мы тратим огромное количество времени на оптимизацию наших маршрутных политик, чтобы трафик предоставлялся клиентам как можно ближе и точнее.
Усовоенный урок
Исторически, при запросе «www.twitter.com», мы предоставляем разные региональные IP, чтобы направить клиента в специально отведенный кластер серверов, основанный на местоположении их DNS сервера. Эта методика GeoDNS является частично не точной из-за того, что мы не можем полагаться на пользователей с определением правильных DNS серверов или на нашу способность определить физическое местоположение DNS серверов в мире. Более того, топология интернета не всегда соответствует географии.
Для решения этой проблемы мы перешли к модели BGP Anycast, в которой мы объявляем тот же маршрут из всех локаций и оптимизируем наш маршрут, чтобы проложить лучший путь от клиента к нашим POP. Таким способом мы достигаем наилучшей работы внутри условий топологии интернета, и нам не нужно полагаться на непредсказуемые выводы о существовании серверов DNS.
Хранение
Каждый день отправляются сотни миллионов твитов. Они обрабатываются, сохраняются, кэшируются, обслуживаются и анализируются. Для такого огромного содержания нам нужна последовательная инфраструктура. Хранение и переписка представляют 45% рабочей зоны инфраструктуры Twitter.
Команды хранения и переписки предоставляют следующие услуги:
- Кластеры Hadoop запускают вычисление и HDFS
- Кластеры Manhattan для всех наших хранилищ ценных ключей низкой секретности
- Хранилища Graph для кластеров MySQL
- Кластеры Blobstore для всех наших больших объектов (видео, картинки, бинарные файлы…)
- Кэш-кластеры
- Кластеры Medsaging
- Реляционные хранилища (MySQL, PostgreSQL и Vertica)
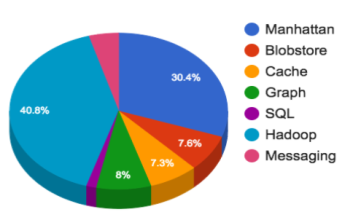 Трудности
Трудности
Хотя существует множество разных трудностей в этом масштабе работы, мульти-владение (multy-tenancy) — это одна из наиболее заметных, с которыми мы встречались. Часто у клиентов крайние случаи, которые могут повлиять на существование владений и вынудить нас построить целенаправленные кластеры. Больше целенаправленных кластеров позволяют увеличить рабочую нагрузку, чтобы все работало как надо.
В нашей инфраструктуре нет сюрпризов, но могу привести несколько интересных фактов:
Hadoop: у нас есть множественные кластеры, хранящие более 500 PB, разделенных на 4 группы (реальное время, обработка, data warehouse и «холодное» хранилище). Наш самый большой кластер состоит из более 10000 узлов. Мы запускаем 150000 приложений и 130 миллионов контейнеров в день.
Manhattan (backend для твитов, личных сообщений, аккаунтов Twitter и т.д.): Мы запускаем несколько кластеров для разных случаев использования, таких, как большое мульти-пользование, поменьше для не общественных, read-only и read/write для heavy write/heavy read паттернов трафика. Кластер read/onlyсправляется с 10000 миллионов QPS, в то время как кластер read/write справляется с миллионами QPS. Самый производительный кластер, который включает центр обработки данных, справляется с десятками миллионов записей.
Graph: наше устаревшее ПО Gizzard/MySQL основано на общем кластере для хранения наших графиков. Flock, наш социальный график, может управлять всплесками более десятков миллионов QPS, усредняя наши серверы MySQL до 30-45 тыс. QPS.
Blobstore: наше хранилище картинок, видео и больших файлов, в котором мы храним сотни миллиардов объектов.
Кэш: наши Redis и Mem кэш-кластеры : кэширование наших пользователей, таймлайнов, твитов и др.
SQL: включает в себя MySQL, PostgreSQL и Vertica. MySQL/PosgreSQL используются, когда нам нужны точная последовательность, управляющая рекламными кампаниями, рекламными обменами так же, как и внутренними инструментами. Vertica – наше основное хранилище, которое часто используется как backend для Tableau, обеспечивающего продажи и организацию пользователей.
Hadoop/HDFS также является backend для нашего лог канала, основанного на Scribe, но на финальной стадии тестирования перехода к Apache Flume, в качестве замены с целью справиться с такими ограничениями как недостаток уровня ограничения/регулирования запросов собирающих клиентов в агрегаторы, отсутствие гарантии доставки для категорий, и для решения вопроса с разрушением памяти. Мы справляемся с более триллиона сообщений в день, и все они распределены в более 500 категорий, собраны и потом выборочно скопированы по всем нашим кластерам.
Хронологическая эволюция
Twitter был создан на основе MySQLи изначально вся база данных хранилась на нем. Мы перешли от маленького инстанса базы данных к крупному, и в итоге пришли к огромным кластерам базы данных. Постепенное передвижение данных в MySQL шаблоны требует упорной и долгой работы, поэтому в апреле 2010 мы представили Gizzard — фреймворк для создания рассредоточенных хранилищ данных.
Экосистема в это время была следующей :
- Скопированные кластеры MySQL
- Gizzard основанный на кластерах MySQL
Сразу же за выпуском Gizzard в мае 2010, мы представили FlockDB, решение для хранения графиков на основе Gizzard и MySQL, и в июне 2010 Snowflake наш сервис для идентификации. В 2010 мы также инвестировали в Hadoop, который изначально предполагался для хранения бэкапов MySQL, но сейчас активно используется для аналитики.
Приблизительно в 2010 мы также добавили Cassandra в качестве хранилища, и хотя он не полностью заменил MySQL из-за отсутствия в нем способности автомасштабирования, он был адаптирован для хранения метрики. Так как трафик значительно рос, нам нужно было увеличивать кластер и в апреле 2014 мы запустили Manhattan: наша распределенная база данных в реальном времени с функцией мультивладения. С тех пор Manhattan стал одним из самых популярных слоев хранения, а Cassandra был исключен.
В декабре 2012 Twitter выпустил обновление, позволяющее выгружать фото. Неофициально, обновление стало возможным при помощи нового решения хранения Blobstore.
Выученный урок
В течение нескольких лет, мигрировав всю базу данных из MySQL в Manhattan, чтобы воспользоваться более высокой доступностью, сниженным временем ожидания и упрощенной разработкой, мы приобрели дополнительные движки для хранения (LSM, b+tree…), чтобы улучшить службу наших шаблонов трафика. Кроме этого, мы извлекли урок из случавшихся аварий и начали защищать слои хранилища от атак, отправляя сигнал противодавления и делая возможным фильтрацию по запросу.
Мы продолжаем акцентировать внимание на предоставлении правильного инструмента для каждой задачи, но это означает полное понимание всех возможных способов использования этих инструментов. Подход типа «всё под одну гребенку» редко работает — избегайте создания быстрых сочетаний клавиш для крайних случаев, так как нет ничего более постоянного, чем временное решение. И наконец, не слишком тиражируйте решения. Во всем есть плюсы и минусы, и необходимость в применении с чувством реальности.
Cache
Хотя Cache занимает 3% нашей инфраструктуры, для Twitter это значимо. Он защищает наши резервные хранилища от heavy read трафика и позволяет хранение объектов, у которых высокая стоимость гидрации. Мы используем несколько кэш-технологий: Redis и Twemcache для огромного масштаба. Точнее, у нас смесь привязанных и multi-tenant кластеров Twitter (twemcache), так же как и кластеры Nighthawk (Redis). Мы переместили всё из нашего главного кэша в Mesos, от голого металла к низким операционным расходам.
Трудности
Масштаб и исполнение — первоначальные трудности для Cache. Мы управляем сотнями кластеров с совокупным уровнем пакета в 320M пакетов/сек., доставляя более 120гб/с нашим клиентам, и нашей целью является доставлять каждый ответ с временем ожидания, ограниченным до 99.9 и 99.9 процентиль даже в случаях всплесков трафика.
Чтобы достичь целей нашего выработанного и низкоуровневого сервиса (SLOs), нам нужно в течение длительного времени оценивать работу наших систем и искать эффективные оптимизации. Чтобы облегчить нам задачу, мы написали rpc-perf для лучшего понимания работы систем кэша. Это стало решающим для планирования вместимости, так как мы мигрировали из привязанных машин в нашу текущую инфраструктуру Mesos. В результате этих попыток оптимизации мы увеличили выработку каждой машины без изменения времени ожидания более, чем в 2 раза. Мы верим, что впереди может быть еще более крупная оптимизация.
Усвоенный урок
Переход к Mesos стал огромной операционной победой. Мы закодировали наши конфигурации и можем постепенно внедрять для сохранения уровня посещения и избежания нанесения вреда постоянным хранилищам, так же, как и их рост и масштабирование с большей уверенностью.
С тысячами соединений на один инстанс twemcachee, любой процесс перезапускается, сеть поддерживается и другие проблемы могут привести к атакам DDoS. После масштабирования это стало больше проблемой и при помощи проведения сопоставительных испытаний мы внедрили правила поглощения, чтобы отсекать соединения с каждым кэшем по отдельности в случае высокого уровня переподключения в противном случае стали бы причиной нарушения наших SLO.
Мы логически разделяем наш кэш по пользователям, твитам, срокам и т.д. и в общем каждый кластер кэша настроен под определенную цель. Основываясь на типе кластера, они справляются с 10-50М QPS и запускают от сотен до тысяч инстансов.
Haplo
Позвольте представить Haplo. Это первоначальный кэш для таймлайна твитов, который поддерживается кастомной версией Refis (внедряющий HybridList). Haplo доступен только для чтения из Timeline Service и для записи совместно Timeline Service и Fanout Service. Он также является одним из нескольких наших сервисов, которые мы еще не мигрировали в Mesos.
- Агрегированные команды от 40М до 100М в секунду
- IO сеть 100мbps на один хост
- Запросы агрегированного сервиса от 800 тыс. в секунду.
Дальнейшее чтение
Yao Yue (@thinkingfish) в течение нескольких лет написал несколько отличных речей и статей о кэше, включая использование нашего Redis и нашей новейшей базы кода Pelikan. Смотрите видео и последние посты в блоге.
Запуская Puppet в масштабе
Мы запускаем широкий спектр сервисов ключевой инфраструктуры, такие как Kerberos, Puppet, Postfix, Bastions, Repositories и Egress Proxies. Мы концентрируем внимание на масштабировании, создании утилит, управлении этими сервисами так же, как и поддержка распространения центра обработки данных и точки входа в сеть. Только за прошлый год мы значительно расширили нашу инфраструктуру POP во многих новых геолокациях, требующих полной смены архитектуры того, как мы планируем, выполняем загрузку и запускаем новые локации.
Мы используем Puppet для руководства конфигурациями и установки пакета kickstart на наших системах. В данном разделе детально описаны некоторые трудности, который мы преодолели и в которых мы руководствуемся инфраструктурой управления конфигурациями.
Трудности
С ростом необходимости удовлетворить нужды наших пользователей мы быстро опередили рост стандартных утилит и практик. У нас более 100 заказчиков в месяц, более 500 модулей и более 1000 ролей. Безусловно, мы сумели сократить количество ролей, модулей и строчек кода во время улучшения качества нашей базы кода.
Разветвление
У нас есть 3 направления, к которым Puppet обращается как к средам (environments), что позволяет нам точно тестировать, выявлять проблемы и наконец внедрять изменения в нашу производственную среду. Мы также делаем скидки на пользовательские направления для более изолированного тестирования. Внедрение изменений от тестирования к самому продукту в настоящее время требует немного ручной подстраховки, но мы постепенно движемся к более автоматизированной системе CI с автоматизированными процессами интеграции/отказа.
База кода
Наше хранилище Puppet содержит больше, чем 1 миллион линий кода, в котором только код Puppet приходится на более чем 100,000 на одно направление. Недавно мы приложили много усилий, чтобы очистить нашу базу кода, уменьшая неиспользуемый и повторяющийся код.
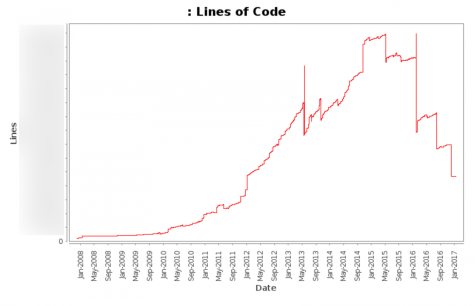 Данный график показывает общее количество наших линий кода (не включая различные автоматически обновленные файлы) начиная с 2008 и до сегодня.
Данный график показывает общее количество наших линий кода (не включая различные автоматически обновленные файлы) начиная с 2008 и до сегодня.
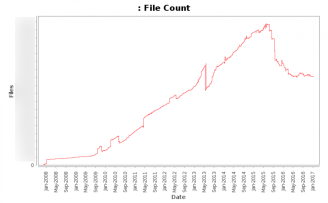 Данный график показывает общее количество наших файлов (не включая различные автоматически обновленные файлы) с 2008 до сегодня.
Данный график показывает общее количество наших файлов (не включая различные автоматически обновленные файлы) с 2008 до сегодня.
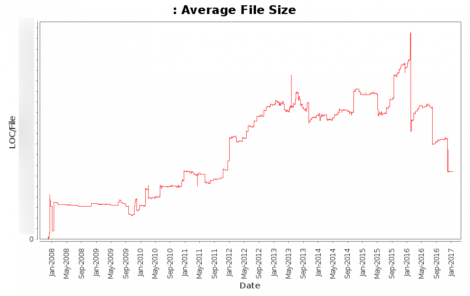 Данный график показывает средний размер наших файлов (не включая различные автоматически обновленныефайлы) с 2008 до сегодня.
Данный график показывает средний размер наших файлов (не включая различные автоматически обновленныефайлы) с 2008 до сегодня.
Большие победы
Самыми большими победами для нашей базы кода стали линтинг кода (автоматическая проверка кода на ошибки), привязки проверки стиля, документация наших лучших наработок и выработка постоянного офисного расписания.
При помощи линтинговой утилизации (puppet-lint) мы смогли приспособиться к общепринятым стандартам линтинга. Мы сократили наши линтинговые ошибки и предупреждения в нашей базе кода на десятки тысяч строк и переделали более 20% базы кода.
После первоначальной очистки, совершать мелкие изменения в базе кода стало куда проще и введя автоматизированную проверку, как вариант, контроль значительно сократил количество стилевых ошибок в базе кода.
С помощью 100 Puppet-разработчиков во всей организации, документирование внутренних практик и практик community стала фактором значительного повышения производительности труда. Благодаря использованию единого документа для обращения, улучшились качество и скорость, с которой код может быть реализован.
Установка четкого рабочего расписания для службы поддержки (иногда по разово) позволило предоставить пользователям помощь тет-а-тет, тогда как каналы чата не всегда предлагали достаточно большой диапазон общения. В результате этого большинство разработчиков улучшили качество и скорость своего кода, понимая свое community, применяя лучшие практики и как лучше всего внедрять изменения.
Мониторинг
Системные метрики обычно не являются полезными (смотрите выступление Caitlin McCaffrey’s Monitorama 2016 здесь), но предоставляют дополнительный контекст для метрик, которые мы считаем полезными.
Некоторыми из самых полезных метрик, о которых мы говорим и которые изображаем являются:
- Ошибки запуска: количество неудачныхзапусков Puppet.
- Длительность запуска: время, которое занимает полное выполнение клиентского запуска Puppet.
- Не запуск: количество запусков Puppet, которое не происходит за ожидаемый промежуток времени.
- Размеры каталога: размер каталогов в Мb.
- Время сборки каталога: время в секундах, которое необходимо каталогу для сборки (компиляции).
- Сборки каталога: количество каталогов, собранных каждым Хозяином.
- Ресурсы файла: количество выбранных файлов.
Каждая из этих метрик отобрана из расчета на 1 хост и сгруппирована по роли, что позволяет постоянно предупреждать и идентифицировать наличие проблем в определенной роли, наборе ролей или событие, имеющее более широкое влияние.
Влияние
При миграции из Puppet 2 в Puppet 3 и обновлении Passenger (оба поста в следующий раз), мы смогли сократить наше среднее время работы Puppet на нашем кластере Mesos от более 30 минут к времени до 5 минут.
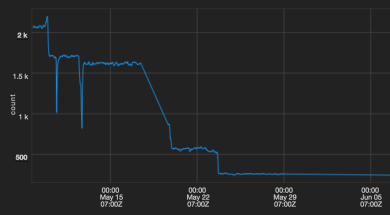 Данный график показывает наше среднее время работы Puppet в секундах на наших кластерах Mesos.
Данный график показывает наше среднее время работы Puppet в секундах на наших кластерах Mesos.
Если Вас интересует более обобщенный процесс обеспечения системы, база данных метаданных (Audubon) и управление жизненным циклом (Wilson) команда Provisioning Engineering недавно делала презентацию на нашем событии #Computer.
Мы не смогли бы достичь этого без упорного труда и преданности всех членов команды Twitter Engineering. Наша благодарность всем нынешним и прошлым инженерам, построивших и внесших вклад в надежность Twitter.
About The Author
Виктор Карабедянц
ИТ директор (CIO), руководитель нескольких DevOps команд. Профессиональный руководитель проектов по внедрению, поддержке ИТ систем и обслуживанию пользователей.